大端和小端
大小端和字节对齐,与 CPU 结构有关,与编译器没关系,只与编译器的默认代码约定规则有关。只要代码约定规则一样(可在代码中加入约定命令),不同编译器编译出来结果是一样的。
我们常常看到“alignment”, “endian”之类的字眼, 但很少有 C 语言教材提到这些概念。 实际上它们是与处理器与内存接口, 编译器类型密切相关的。
端模式(Byte Endian) 是指字节在内存中的组织,所以也称它为Byte Ordering。这边所谓的端模式一般就是指大端或者小端存储,也就是每个字节的实际排放顺序,上面已经讨论过字节在内存中如何进行对齐,这边讨论字节的常见排放顺序。
数据寻址时,一般读取的都是低位字节的地址(即存储数据的可能占用多个地址,但低位地址代表了这个数据的地址)。C 中的数据类型都是从内存的低地址向高地址扩展,取址运算”&”都是取低地址。 所以就有高位地址和地位地址区别,一般来说数字大的就是高地址,数字小的是地址:比如 0x1000 相对于 0x1003 来说是低地址。数据低位和数据高位:比如 0x012345678 0x01 是数据高位(即使 Most Significant Byte,MSB 位),而 0x78 是数据低地址位(Least Significant Byte,LSB)。
注意:有些地方 MSB 也可以代表 Most Significant Bit,LSB 则代表 Least Significant Bit 根据具体的场景来判别。如:FM25W256 铁电或者 EEPROM 中,描述的 MSB/LSB 根据时序图往往可以判别代表的高地位而不是字节。
端模式(Byte Endian)简述
大端模式:数据低位存放到地址高位。比如:存储数据0x01234567,按照0x01->1000,0x23->1001,0x45->1002,0x67->1003这种顺序存储。通讯中大都采用大段模式,因为数据通讯时,直接可以按照一个个位进行解析,无需每次调换顺序,大端模式往往在通讯中被广泛使用。
小端模式:一般也称作内存模式,数据高位存放到地址高位。比如:存储数据0x01234567,按照0x67->1000,0x45->1001,0x23->1002,0x01->1003这种顺序存储。嵌入式芯片中目前主流就是小端模式,绝大多数ARM芯片默认也为小端模式,但可以进行更改设置,传统的51芯片为大端模式。
除了大小段模式外,还有一些协议自定义的转换标准,有的协议将两个字节(16bit)作为一个整体,如:传送数据0x00010203(按照内存模式/小端模式传送)时,会解析为0x0100,0x0302,具体分析,实际上采用的是大端模式,每次传输数据时,将16个作为个整体进行解析。
详细分析
最近阮一峰老师的博客刚好也写了一篇有关大小端的文章,老实说,大小端本人也接触很久了,但也一直较为困惑,另外时间一长每次就忘了哪个是大端哪个是小端,这边给出一些个人的理解和分析。
描述大小端时有一点表示的比较模糊,这边前后有两种含义:1.内存的寻址肯定是从低往高的,所以下面表示的前或者后,都是以内存作为参照,前表示内存的低地址,后表示内存高地址;2.通信过程中,传输在前表示先被传输打印过来的值,传输在后表示后被传输打印出来的值(传输的过程也需要明确一点,数据的传输打印不是被逐个挤到后面去的,而是在后面以append的形式显示,后来的数据显示在后方)。明确了这两点内容这边详细谈下大小端:
- 大端字节序:高位字节在前,低位字节在后,这是人类读写数值的方法。内存中低地址对应数据的高位,传输中数据高位先被打印出来,因为先被打印出来(而打印按照从左往右的顺序逐个显示),所以例如:0x789A6B 就会显示为 78 9A 6B 同 0x789A6B 次序一致,这种更加符合人的阅读习惯。大端更加符合人的阅读习惯,自左往右的依次增高的阅读习惯。
- 小端字节序:低位字节在前,高位字节在后,即以0x1122形式储存。内存中低地址对应数据的低位,传输中数据低位先被打印出来,因为先被打印出来(而打印按照从左往右的顺序逐个显示),所以例如:0x789A6B 就会显示为 6B 9A 78 看起来并不容易阅读。小端比较符合人的一般思维逻辑(注意仅仅符合思维逻辑,并不符合阅读习惯)。
这边有些同学可能又有疑惑,为何 6B 可以解析为 6B(01101011) 而不是反过来 D6(11010110) 呢?事实上计算机在传输过程中确实没有一个统一的标准,串口传输数据时一般都满足原则:先传输字符的低位,后传输字符的高位;然而在某些通信协议中却刚好相反,如 SPI 中,就是先传输字符的高位,后传输字符的低位的方式。
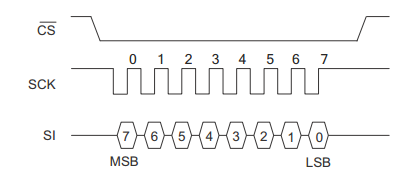
- 以下内容引用自阮一峰老师的博客:
首先,为什么会有小端字节序?答案是,计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序。
但是,人类还是习惯读写大端字节序。所以,除了计算机的内部处理,其他的场合几乎都是大端字节序,比如网络传输和文件储存。
个人认为该内容有待斟酌,如 51 单片机就是大端模式,另外很多 ARM 的 MCU 都是默认小端,且可以用户自己设置选用大端还是小端模式的。个人认为计算机内部并不会因为大小端而影响效率,在设计芯片时应该已经决定了它的特性。小端模式在不考虑传输,人工查看的前提下,对例如:00 78 9A 6B 用 6B所对应的地址来表示 0x789A6B 这个数据数据的存储位置,也是有一定道理的。
记忆方法
在乔纳森·斯威夫特的著名讽刺小说《格列夫游记》中,小人国内部分裂成Big-endian和Little-endian两派,区别在于一派要求从鸡蛋的大头把鸡蛋打破,另一派要求从鸡蛋的小头把鸡蛋打破。斯威夫特借以讽刺英国的政党之争,在计算机工业中指数据储存顺序的分歧。
这边首先需要有个参照物,计算机按照从低位往高位寻址这是毋容置疑的,存储时,也都是讲内存的低位用完后,指针加一,再使用更高的位。大端意味着内存的低位存储了数据的高位,小端则是内存的低位对应了数据的低位。
测试大小端参考代码:
|
|
参考链接:
http://blog.csdn.net/vvzaixian/article/details/7067221
http://www.360doc.com/content/12/0413/10/1016783_203216902.shtml
https://my.oschina.net/chaenomeles/blog/673091
http://blog.sina.com.cn/s/blog_4afb1c4c010009oa.html
http://www.ruanyifeng.com/blog/2016/11/byte-order.html